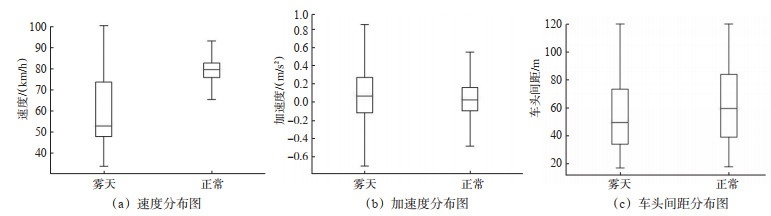
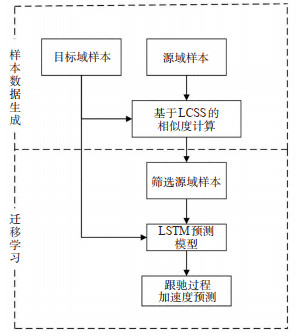
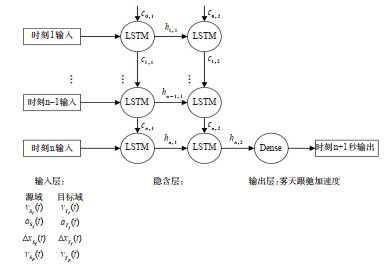
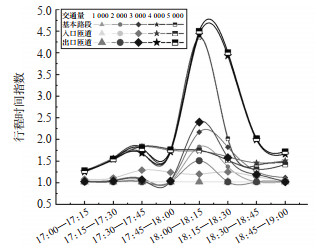
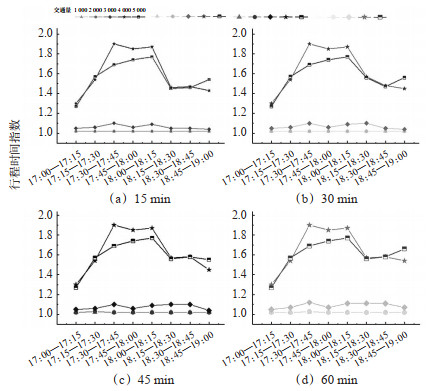
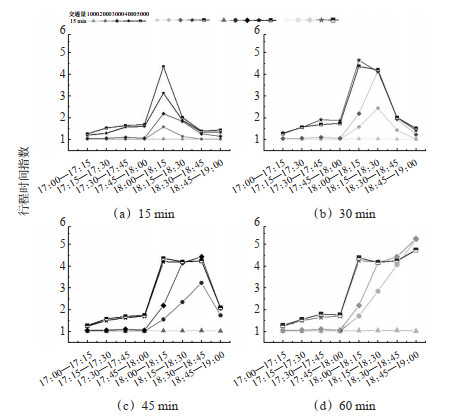
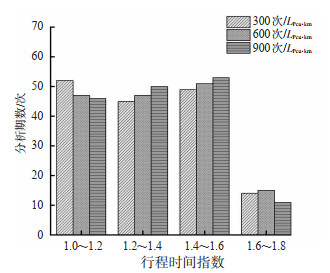
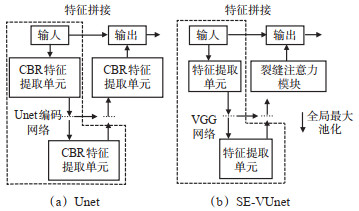
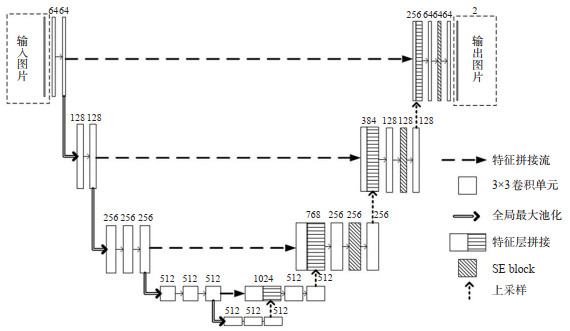
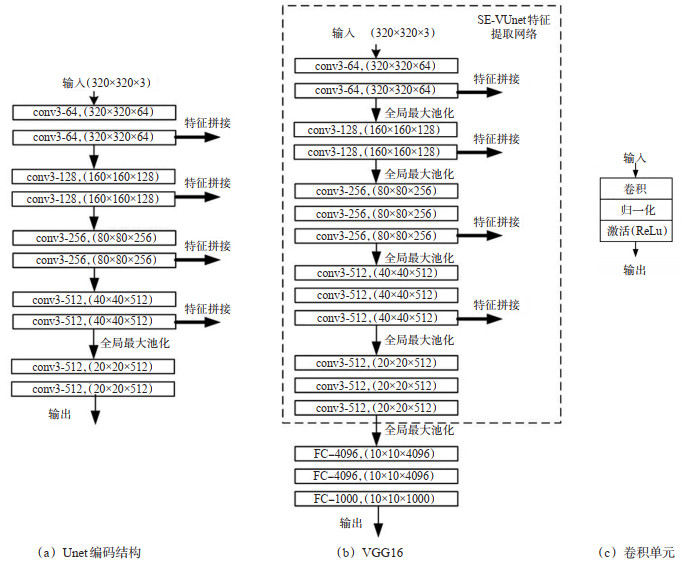
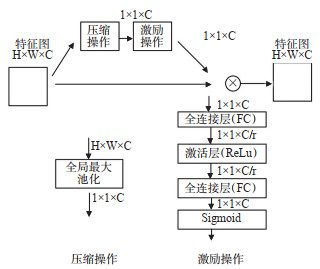
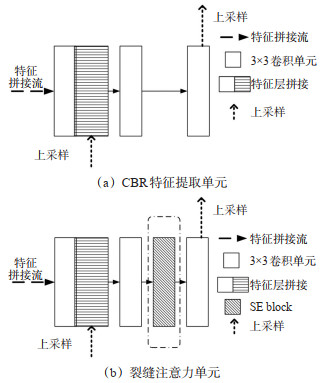
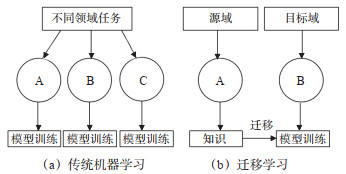
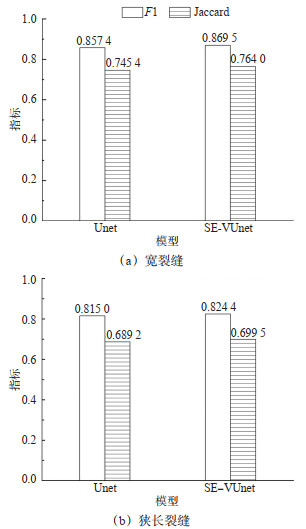
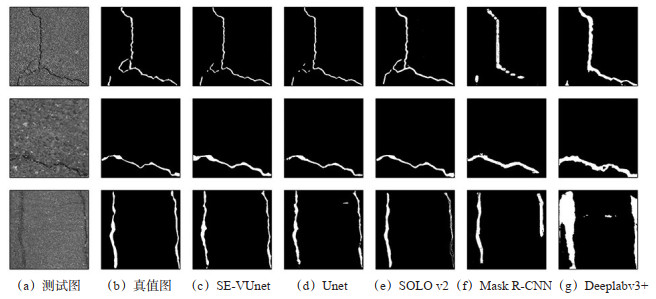
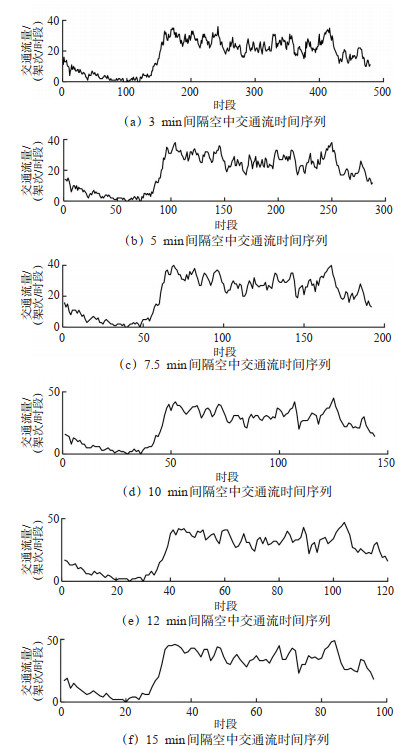
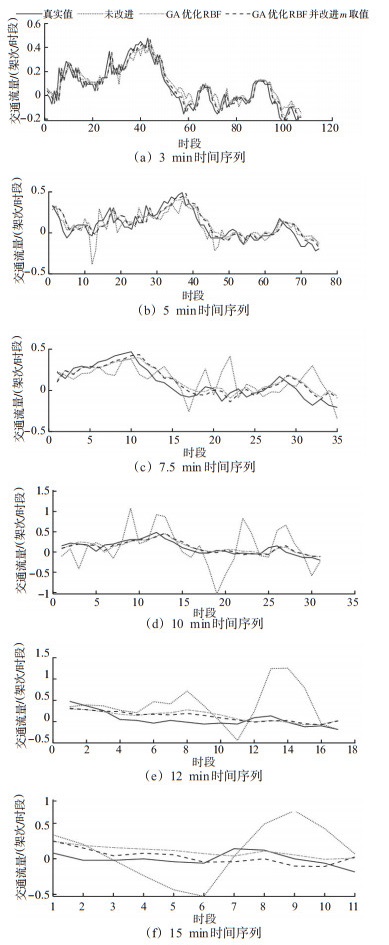
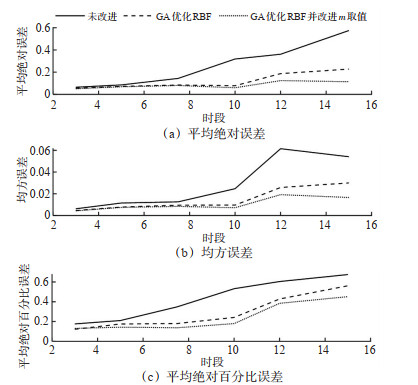
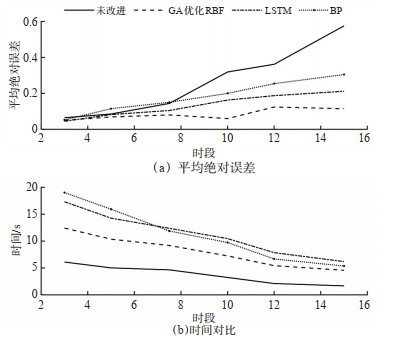
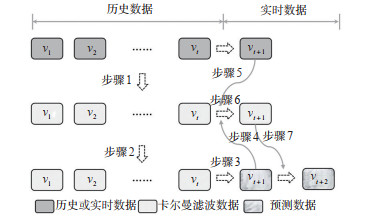
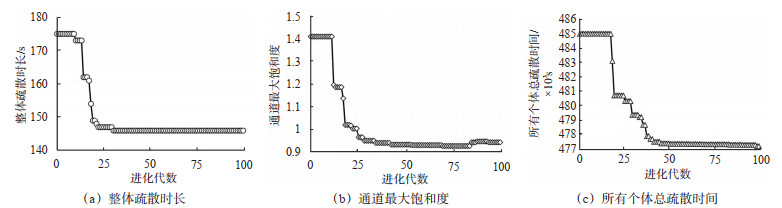
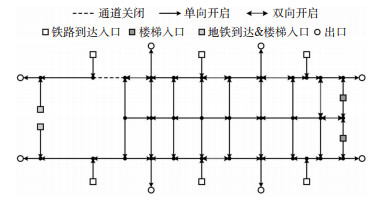
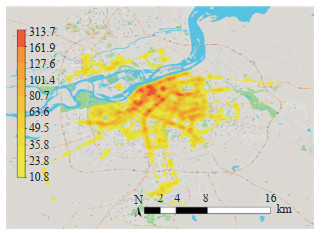
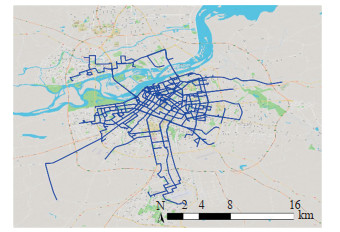
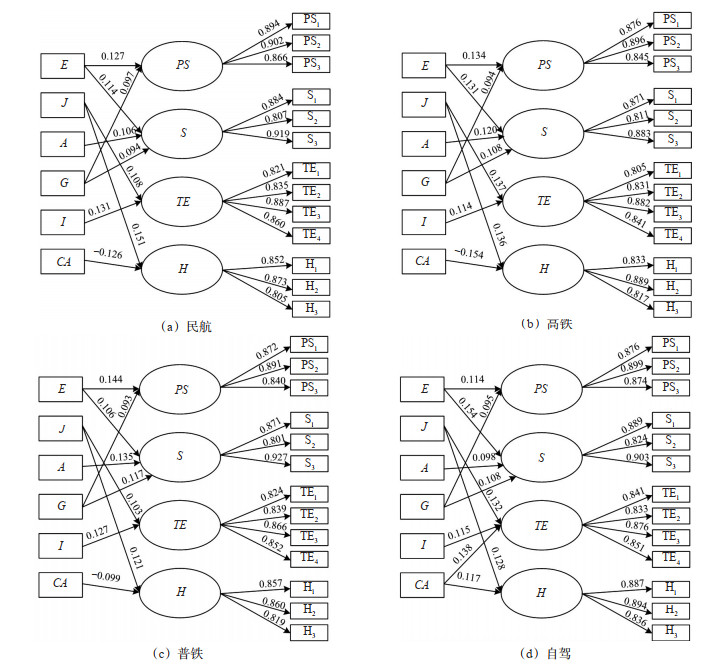
Abstract:
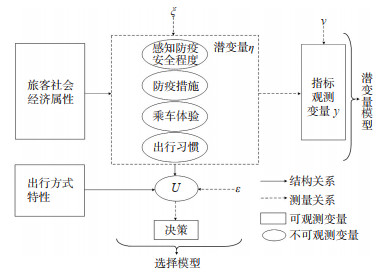
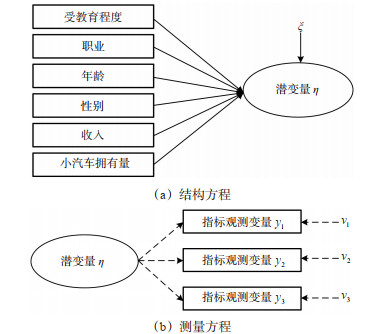
The impact of COVID-19 on long-distance intercity travel is enormous. Existing studies have investigated the impact of COVID-19 on intercity travel at the early stage of the epidemic outbreak, while few of them have studied its impact during the periods with regular prevention and control measures. To fill the gap, this paper focuses on the mode choice behavior of long-distance intercity travel under the impact of regular prevention and control measures of the COVID-19 epidemic. First, a set of multiple indicators and multiple causes (MIMIC) models are developed for civil aviation, high-speed rail, train, and passenger car, independently, and each covers the four modes. The perceived level of safety of prevention measures, epidemic prevention strategies, riding experience, and travel habits are considered in the MIMIC choice behavior model, which are used to explore the relationship between observed and latent variables, to identify the parameters of the model, and to estimate each latent variable. Secondly, to investigate the impact of passengers' psychology on their travel mode choices, a MIMIC-Logit model considering the characteristics of travel modes, socio-economic attributes of passengers, and latent variables is developed. Then, assuming that the random coefficients of passengers' travel expenses, travel time, and travel distance follow a normal distribution, the Halton sequence drawn from the original data through 1000 samplings is used to estimate the utility coefficients of the MIMIC-Logit model. Lastly, the survey data of passengers arriving in Xi'an between April and June 2021 is employed to validate the proposed model. Study results show that (1) the goodness of fit and hit ratio of the MIMIC-Logit model with latent variables is 43.621% and 83.312%, respectively, which are higher than the comparative multinomial-Logit model and the random coefficient Logit model; (2) the preferences of passengers towards different travel modes of travel expenses, travel time, and travel distance are heterogeneous, and the characteristics of travel modes, socio-economic attributes, and latent variables all have a significant impact on mode choices; (3) when the variables representing perceived level of safety of the COVID-19 prevention measures and epidemic prevention strategies is increased by 100%, the probability of choosing civil aviation is increased by 23.207% and 21.349%, respectively; (4) when the variable representing travel experience is increased by 100%, the probability of passengers choosing high-speed rail is increased by 18.229%. In general, the proposed method reveals that the latent variables representing passenger's psychology has a significant impact on mode choice behavior, and the probability of choosing high-speed rail and civil aviation can be increased by improving the perceived level of safety of prevention measures, epidemic prevention strategies, and riding experience.